Kubernetes
Kubernetes is open source container management platform.
It
- help you run containers at scale
- provide objects and APIs for building applications
Nodes
Nodes are the machines that make up a Kubernetes cluster. These can be physical or virtual.
Two types of nodes:
- Control-plane (which makes up the Control Plane) is the brains of the cluster
- Worker-node (which makes up the Data Plane) runs the actual container images (via pods)
Objects
Kubernetes objects are entities that are used to represent the state of the cluster.
The cluster does its best to ensure it exists as defined (by the object). This is the cluster's desired state. The object is a record intent.
Kubernetes is always working to make an object's current state equal to the object's desired state.
The desired state could describe:
- What pods (containers) are running, and on which nodes
- IP endpoints that map to a logical group of containers
- How many replicas of a container are running
- Other stuff
A Pod is a thin wrapper around one or more containers
A DaemonSet implements a single instance of a pod on a worker node
A Deployment details how to roll out (or roll back) across versions of your application
A ReplicaSet ensures a defined number of pods are always running
A Job ensures a pod properly runs to completion
A Service maps a fixed IP address to a logical group of pods
A Label key/value pairs used for association and filtering
Architecture
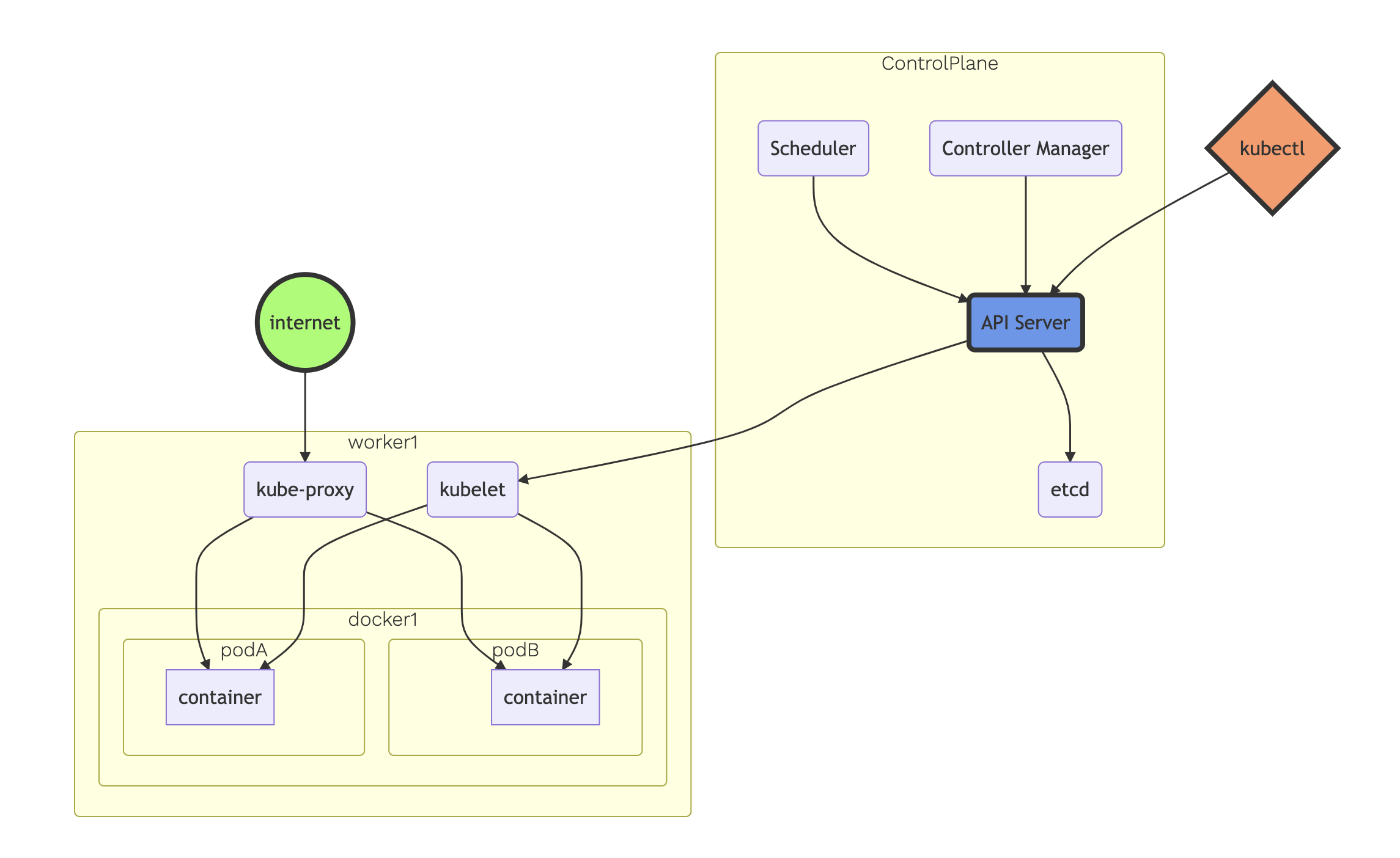
Control Plane
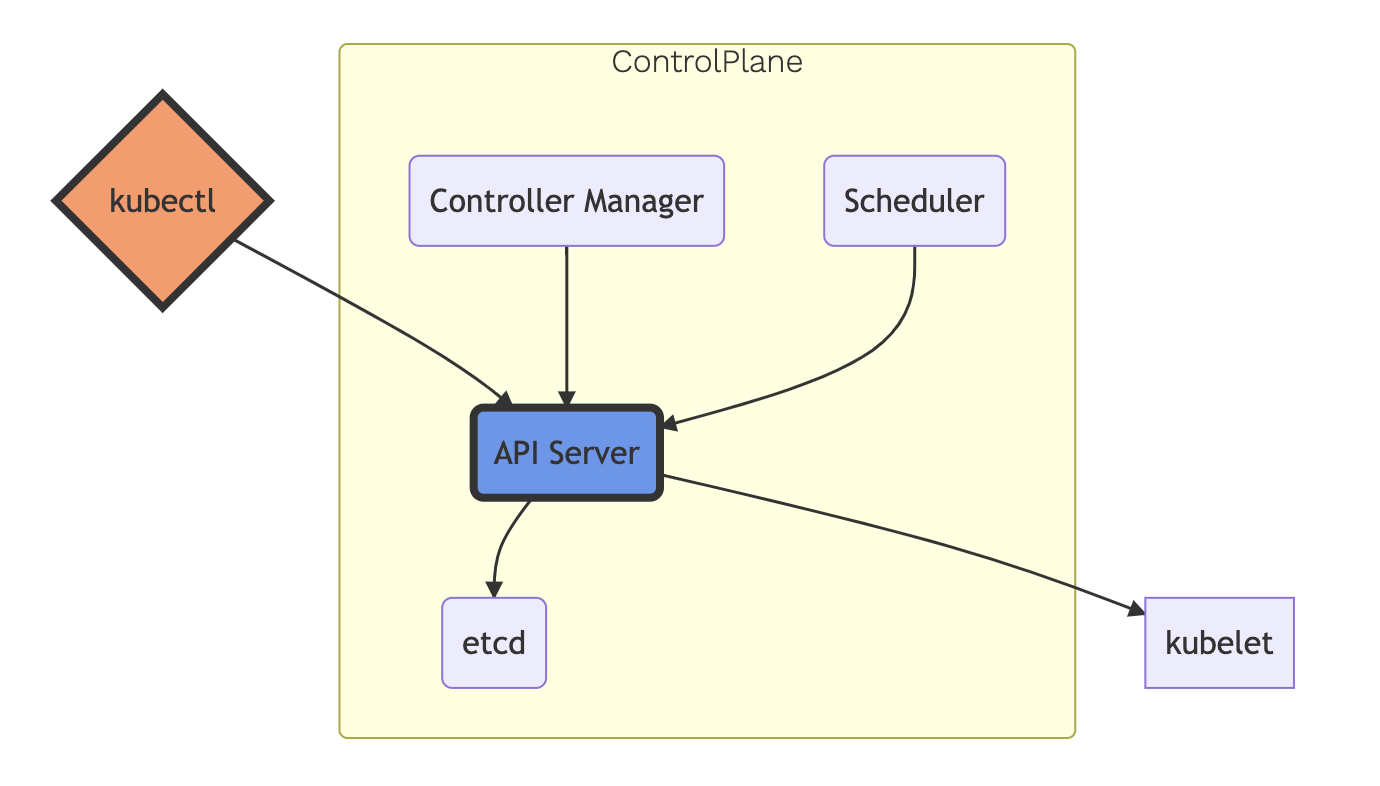
- One or More API Servers: Entry point for REST / kubectl
- etcd: Distributed key/value store
- Controller-manager: Always evaluating current vs desired state
- Scheduler: Schedules pods to worker nodes
Data Plane
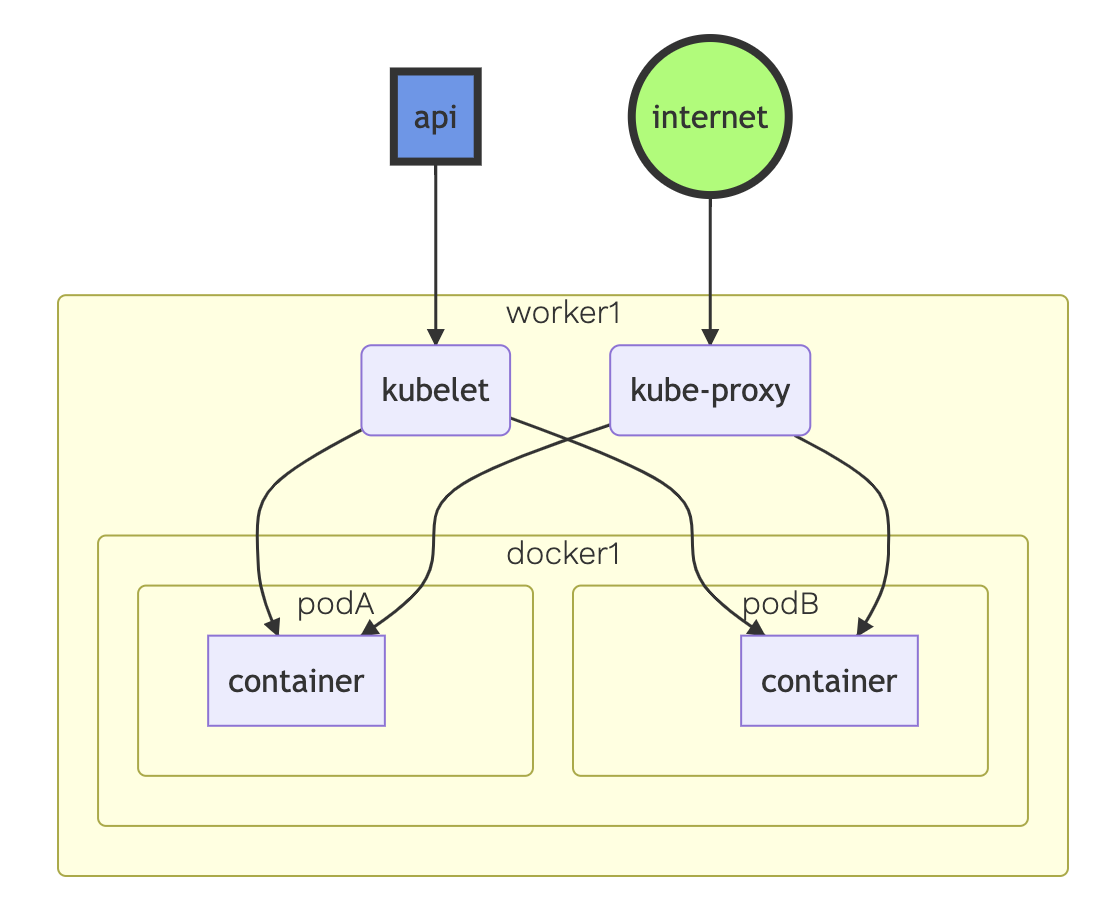
- Made up of worker nodes
- kubelet: Acts as a conduit between the API server and the node
- kube-proxy: Manages IP translation and routing
Helm
Helm is a package manager for kubernetes. It packages multiple kubernetes resources into a single logical deployment unit called a Chart.
Health Checks
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
Liveliness probes are used in K8s to know when a prod is alive or dead. K8s will kill and recreate the pod when a liveliness probe doesn't pass
Readiness probes are used in K8s to know when a pod is ready to serve traffic. If a readiness probe fails, traffic will not be sent to the pod.
Auto Scaling
Two forms of auto scaling:
- Horizontal Pod Autoscaler (HPA) - scales the pods in a deployment or replica set. It is implemented as a K8s API resource and a controller.
- The controller manager queries the resource utilization against the metrics specified in each HorizontalPodAutoscaler definition.
- It obtains the metrics from either the resource metrics API (for per-pod resource metrics), or the custom metrics API (for all other metrics).
- Cluster Autoscaler (CA) - component that automatically adjusts the size of a Kubernetes Cluster so that all pods have a place to run and there are no unneeded nodes.
Role-based Access Control (RBAC)
RBAC is a method of regulating access to computer or network resources based on the roles of individual users within an enterprise.
The logical components:
- Entity - A group/user/service account. The identity representating the application that wants to execute certain operations (actions) and requires permission to do so.
- Resource - A pod/service/secret that the entity wants to access using the certain operations.
- Role - Used to define therules for the actions the entity can take on various resources.
- Role binding - Attaches a role to an entity. This dictates the set of actions permitted by the entity on the specified resources. Two types roles/role bindings:
- Role/RoleBinding - authorization in a namespace
- ClusterRole/ClusterRoleBinding- authorization cluster-wide
- Namespace - They provide a unique scope for object names. They are intended to be used in multi-tenant environments to create virutal kubernetes clusters on the same physical cluster.
Amazon EC2 Security Groups + Kubernetes pods
We can use Security Groups to define inbound and outbound network traffic to and from pods.
Kubernetes Service
Let's say we have nginx running cluster wide. We can talk to these pods directly theoretically, but what happens if a node dies? The pods die, but the deployment will create new ones, with different IPs. How do we get this new IP?
This is where kubernetes service comes in.
A Kubernetes service is an abstraction that defines logical set of pods running somewhere in your cluster.
When created, each Service is assined a unique IP address (aka clusterIP). This address is tied to the lifespan of the Service and will not change while the Service is alive.
Pods can be configured to talk to the Service, and that communication will be load-balanced automatically to some pods that are members of the Service.
Accessing the Service
Two ways we can find a Service:
- environment variables
- DNS
Environment Variables
When a pod runs on a node, kubelet adds a set of environment variables for each active Service.
What happens if we were to run a pod first and then make it a Service? Environment variables won't be there
You'd have to kill the pods and wait for the Deployment to recreate them. At this point, the Service will already have existed and the env variables will be set.
DNS
Kubernetes offers a DNS cluster add-on Service that automatically assigns DNS names to other Services.
Exposing the Service
There may be a need to expose a Service onto an external IP address. Kubernetes support this in two ways: NodePort and LoadBalancer.
Ingress
Ingress exposes HTTP and HTTPS routes from outside the cluster to Services within the cluster.
The routing itself is controlled by rules defined on the Ingress resource.
Ingress doesn't expose arbitrary ports or protocols. If you want to expose services other than HTTP or HTTPS, use
NodePortorLoadBalancer.
Ingress Controller is responsible for fulfilling the Ingress, commonly with a load balancer. It may configure your edge router or additional frontends to help handle the traffic.
You need an ingress controller to satisfy an ingress. Just having an ingress doesn't do anything.
Assigning Pods to Nodes
We can configure a pod to only run on specific nodes, or prefer certain nodes.
This usually isn't necessary, the scheduler will do a reasonable job of this. There may be specific cases where you want to put a pod in a node with an SSD, or two pods together.
Method 1 - NodeSelector
nodeSelector is a field of PodSpec in the form of a map of key-value pairs.
For a pod to be eligible to run on the node, the node must have each of the specified key-value pairs as labels.
Method 2 - Affinity and Anti-affinity
The nodeSelector is a very basic way of adding constraints to pods. The affinity/anti-affinity feature extends the types of constraints you can express.
Key enhancements:
- More expressive language (not a simple AND)
- You can indicate a rule is a preference rather than a requirement. (If it doesn't meet the rule, the pod will still be scheduled.)
- You can constrain against labels on other pods running on the nodes (rather than labels on the pod)
Node Affinity
Two types of node affinity:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
These are basically hard and soft requirements, respectively.
The "IgnoredDuringExecution" basically means if a pod's labels change at runtime so that it doesn't meet the rule, it'll still run on the node.
Stateful Containers Using StatefulSet
StatefulSet manages the deployment and scaling of a set of Pods.
It provides guarantees about the ordering and uniqueness of these Pods. (Not sure what ordering here is, or what it means by unique).
This is good for applications that require:
- Stable, unique network identifiers
- Stable, persistent storage
- Ordered, graceful deployment and scaling
- Ordered, automated rolling updates
Container Storage Interface (CSI)
(This isn't related directly to stateful containers, but it is relevant when working with storage for the statefule container example).
The Container Storage Interface is a standard for exposing arbitrary block and file storage systems to containerized workloads on Container Orchestration Systems (COs) like Kubernetes.
Using CSI, 3P storage providers can write and deploy plugins exposing new storage systems in Kubernetes without ever having to touch the core Kubernetes code.
Third party for example, Amazon Elastic Block Store (Amazon EBS). Amazon EBS has a CSI driver that provides this interface to allow Amazon EKS to manage the lifecycle of Amazon EBS volumes for persistent volumes.
Kubernetes Secrets
Kuberbetes can store secrets that pods can access via a mounted volume. K8s store these secrets in a Base64 encoding, but a more secure way is preferred.
We can use AWS Key Management Service (KMS) Customer Managed Keys (CMK) to do so.
Sealed Secrets
Sealed Secrets provides a mechanism to encrypt a Secret object to that it is sage to store - even to a public repo.
It can only be decrypted by the controller running in the K8s cluster.
This is composed of two parts:
- A cluster-side controller
- A client-side utility, kubeseal
The steps:
- On Start Up
- The controller looks for a cluster-wide private/public key pair. If not found, it'll generate a new 4096 bit RSA key pair.
- The private key is persisted in a Secret object in the controller's namespace.
- The public key is made publicly available
- During encrpytion
- Each value in the original Secret is symmetrically encrypted using AES-256 with a randomly generated session key.
- The session key is asymmetrically encryped with the controller's public key using SHA256 and the original Secret's namespace/name as the input parameter.
- The output string is: length (2 bytes) of encrypted session key + encrypted session key + encrypted Secret
- During deployment of SealedSecret
- The controller picks up the secret
- Unseals it using the private key
- Creates a Secrete resource.
- During decryption
- The SealedSecret's name/namepace is used as the input parameter.
kubeseal is used for creating a SealedSecret custom resource definition (CRD) from a Secret resource definition using the public key.
Users
Two types of users:
- Normal users (not managed by Kubernetes)
- Service Accounts (managed by Kubernetes)
From Doc: Kubernetes does not have objects which represent normal user accounts. Normal users cannot be added to a cluster through an API call.